DETR三则
本文讨论DETR系列网络,包括DETR、DeformableDETR和RTDETR(持续更新)。
DETR
DETR概述
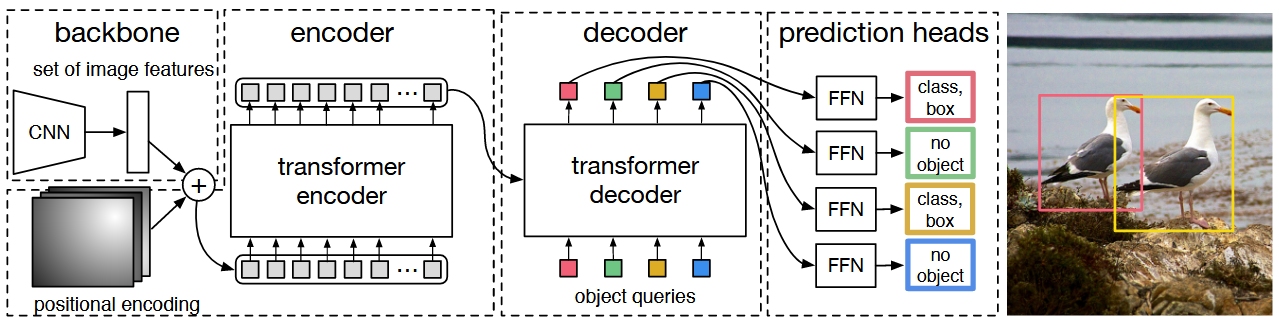
DETR是Facebook团队于2020年提出的基于Transformer的端到端目标检测,没有非极大值抑制 NMS 后处理步骤、没有anchor等先验知识和约束,整个由网络实现端到端的目标检测实现,大大简化了目标检测的框架。现有的目标检测模型的后处理部分采用NMS来抑制不同大小的框,导致后处理部分过于庞大。而DETR实现了一种端到端的目标检测算法。如图所示:1、Backbone用来提取图像的特征,一般采用Resnet50网络,原始DETR使用Imagenet预训练好的Resnet,之后提取出的特征图展平之后送入到Transformer结构的Encoder和Decoder中。2、Encoder是为了更好的学习全局信息,为了让Decoder更好的出预测框,简单而言就是构建出目标的全局交互信息,这样就知道了物体的位置和类别,避免了像RCNN一样同一个地方出好多框。3、Decoder将预测出的目标框进行输出。这里,原作者强行将输出的框数定义为了100,也就是无论如何,Decoder都会输出100个框。4、为了能和GT框进行匹配,作者在这里将问题看做是一个集合预测的问题,通过二分图匹配的方法设置。
从整体结构来看,模型整体没用到anchor生成的那一套逻辑,因此也不需要用NMS来筛选框。需要注意的是,该文诞生时Vit还未发表。
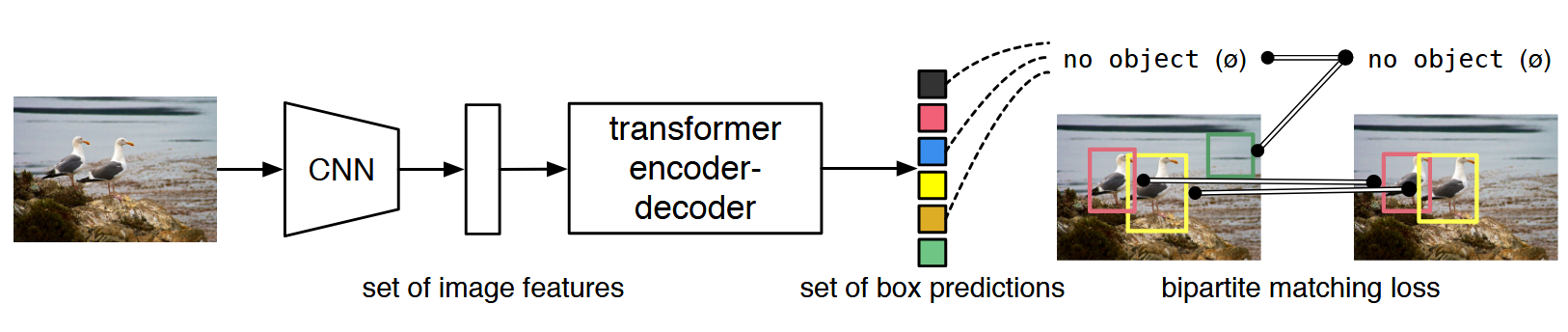
二分图算法
二分图算法是通过计算损失矩阵(Cost matrix),找到损失最低的组合,如匈牙利算法,工程上常用scipy包中的linear-sum-assgnment函数进行计算。在DETR这里就是将这100个框与GT框进行组合配对。原文中的公示如下所示:
通过二分图算法得到最佳的预测-GT框匹配后其实任务并未结束,因为原文还并未计算真正的损失,这一步只是工程化的一部分,只是为了实现“端到端”的框输出,避免一物多框。得到优化后的预测-GT框后,就开始计算模型的损失函数,这部分内容和平常的目标检测模型方法大差不差。
Deformable DETR
虽然DETR已经展现了很好的创新,但DETR存在两个问题,一是在小目标检测上的精度不如其他模型,二是收敛慢,需要训练500个epoch才可以收敛。Deformable DETR\cite{zhu2020deformable}改机了这些问题。Deformable DETR提出了可变形卷积(DCN),在卷积当中引入了学习空间几何形变的能力,让卷积自动的去学习需要需要卷积的周围像素,以此可以适应更加复杂的几何形变任务。作者使用DCN对原来的Transformer注意力部分进行改进,提出了Deformable Attention模块。此外,作者将backbone不同层的输出提取出来构成多尺度特征这样可以增加小尺度目标的特征信息,提高小尺度目标的检出率。
RT-DETR
Zhao等人针对DETR的巨大计算成本设计了一种实时目标检测DETR网络(RT-Detr),如图所示。
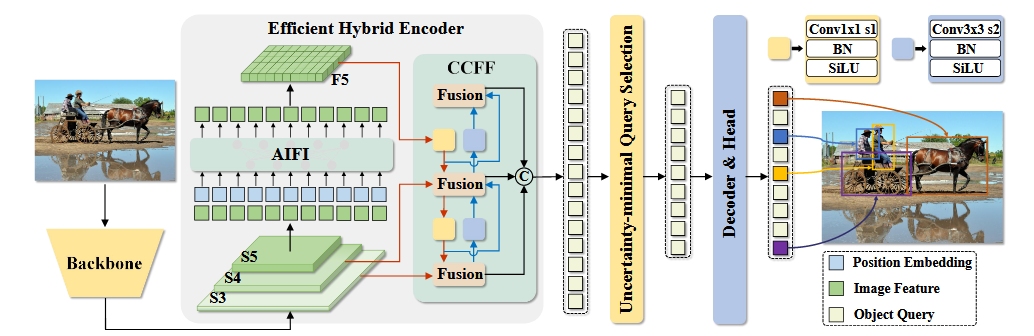
原始的DETR虽然采用了无NMS设计,但其采用Transformer架构给模型带来了巨大的计算成本,严重制约了模型的实时性。作者通过分析,认为是原始DETR中多尺度分辨率的编码器和对象查询带来了巨大的时间成本,RT-DETR针对这两部分进行了调整。
RT-DETR模型整体依旧保持了与原始DETR类似的结构设计,即backbone、编码器、类别查询。模型首先通过backbone进行特征提取得到S3、S4、S5三种不同尺度的特征。在编码器部分,RT-DETR 创新性将CNN卷积神经网络加入了进来以减少transformer的计算量,高效混合编码器由AIFI和CCFF构成,AIFI只对backbone 生成的最高层特征图 feature map S5 进行展平做自注意力机制并加入位置编码(图中蓝色部分),CCFF月PAN类似,将S3、S4和AIFI输出的特征进行多尺度融合,整体采用CNN设计。从编码器处理完成之后,RT-DETR 会通过一些处理选择出 topK 的 anchors 作为 object queries 输入到解码器中,这个地方在训练和预测时的处理是不相同的。
